 Mastodon
MastodonMotivation
Vor einiger Zeit habe ich mit Wolfgang über die offene Prozessor-Architektur RISC-V diskutiert, insbesondere auf welcher Plattform man mal eigene Versuche durchführen könnte.
Sein Vorschlag war das Colorlight-5a-75b Board mit RISC-V SoftCore im FPGA unter Litex/migen als preiswerte Möglichkeit (~18€ !) der Umsetzung (siehe hierzu auch diesen Hackaday-Artikel).
Hiermit könnte man gleichzeitig etwas über FPGAs und RISC-V lernen. Na denn …
1. Zum Aufwärmen
Auf dem CCC Sommer-Camp letztes Jahr stellten mitro & xobs ihren Fomu USB-Stick vor (jeder, der die Toolchain installiert hatte, bekam die Hardware für lau). Wolfgang hat mir seinen Fomu überlassen um mal mit dem Litex-Projekt warm zu werden (ich war nicht auf dem Camp). Zu diesem Projekt existiert eine komplette Anleitung.
Nach dem Durcharbeiten hat man so eine ungefähre Vorstellung, worum es bei Litex/migen geht. Der Witz ist ‘doing hardware by software’, wobei als Software hier Python gemeint ist. LiteX ersetzt hier herstellerspezifische Tools komplett, man programmiert in Python mit migen spezifischen Erweiterungen die gewünschte Hardware-Funktion. Hilfreich, um reinzukommen ist z.B. auch dieses Tutorial.
Damit das Ganze etwas einfacher wird, gibt es bereits komplette Hardware-Einheiten (z.B. für SPI, Ethernet, DRAM & SDCard) inkl. passender Board-Informationen im Rahmen des Litex-‘Frameworks’.
2. Wie ‘geht’ denn nun FPGA?
Aktuelle FPGAs kombinieren typischerweise verschiedene änderbar konfigurierbare Funktionen auf einem Chip (daher: rekonfigurierbare Logik).
- Zu diesen Funktionen zählen Logikblöcke LUT (‘Lookup-Table’) die typischerweise mehrere Eingänge (4-6) mit definierbarer Logikfunktion (als Wahrheitstabelle formuliert) auf einen Ausgang umsetzen (gezählt werden hier 1000er Blöcke - abgekürzt häufig in der Typbezeichnung des FPGA-Bausteins wiederzufinden).
- Daneben gibt es Speicherblöcke (‘Memory’) um beliebige statische & dynamische Daten abzulegen.
- Außerdem sind PLLs (1, 2, 4 oder ggf. noch mehr) zur Generierung von Taktsignalen (‘clock’) vorhanden.
- Häufig findet man auch fertige Funktionsblöcke wie im Beispiel unten die Multiplikations- und SERDES-Blöcke.
- Gelegentlich finden sich auch ganze DSPs integriert.
Hier mal eine Übersicht des auf dem Colorlight-Board eingesetzten FPGA von Lattice, einem ECP5-25. Man erkennt die Einordnung des Herstellers in seinem Produktspektrum, also die Variabilität bei nur einem Produkt (es gibt zahllose ähnliche Produktreihen allein von diesem Hersteller - und derer gibt es vier Namhafte: AMD/Xilinx, Intel/Altera sowie - deutlich kleiner - Microchip & Lattice).
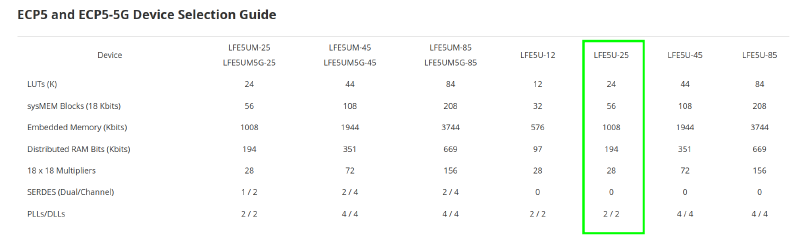
FPGAs werden im eigentlichen Sinne nicht programmiert, sondern konfiguriert. Die Konfiguration wird mit speziellen Beschreibungssprachen erzeugt, den sogenannten HDLs (‘Hardware Definition Languages’). Dazu zählen VHDL, Verilog und in jüngerer Zeit eben auch migen, das hier unter Python/Litex zum Einsatz kommt (wir ignorieren hier mal die Fortentwicklung von migen zu nmigen/’new migen’…)
3. Butter bei die Fische
Im vorliegenden Fall wird das Board Colorlight-5a-75b verwendet. Eine Board-Spezifikation in LiteX liegt also bereits vor - gut, wenn man sowas zum ersten Mal macht … 😉 Von diesen Daten ausgehend, kann man erste eigene Experimente durchführen. Parallel empfiehlt es sich, ein paar YouTube-Videos zum Thema ‘Litex’ anzuschauen (leider habe ich mir nicht notiert, was ich dort alles gesehen habe!).
Die Idee war, Adafruit’s Neopixel LED-Ketten mittels Hardware-Einheit anzusteuern (eine Internet-Recherche in 9/2020 ergab nur Lösungen in VHDL & Verilog - unbrauchbar für meinen Ansatz). Da die Neopixel ziemlich harte Timing-Anforderungen stellen (800 kHz) und z.B. mit Espressif’s ESP32 immer mal wieder Probleme bereiten (parallel zu einer aktiven I2S-Schnittstelle z.B. 🙁) ginge hier doch vielleicht was mit unabhängiger Hardware?!
3.1 Problemanalyse
Zunächst gilt es, das Protokoll zu verstehen (Super Idee 😉). Hierzu existiert eine Herstellerspezifikation und eine Problemanalyse von dritter Seite. Ich habe mir das Wichtigste herausdestilliert:
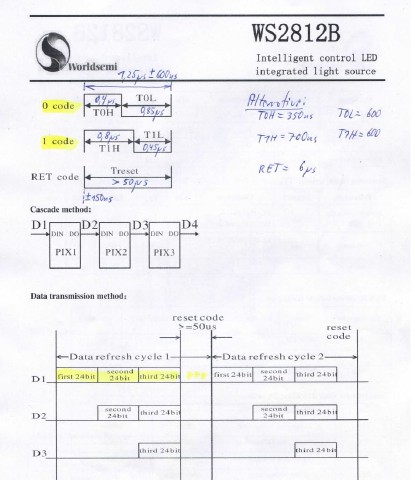

Daraus kann man direkt einen finiten Automat basteln (soweit zur Theorie, die vorliegende Grafik wurde natürlich erst im Nachhinein erstellt … 😉):
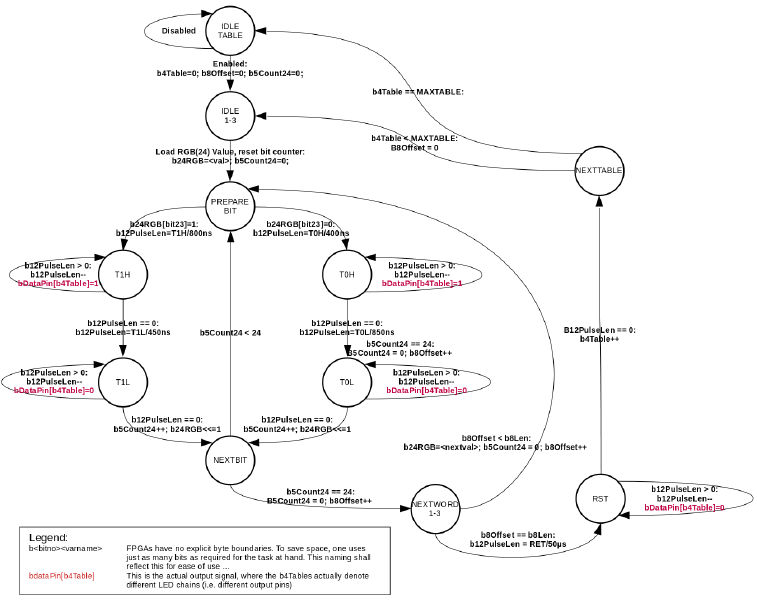
3.2 Ausführung
Die Logik kann man dann ziemlich ‘straight’ runterprogrammieren mit den in migen bereits vorhandenen ‘Finite State Machines’ (FSM). Hier der Auszug der relevanten Python Klasse (Hinweis: Enthält bereits die notwendigen Timing-Anpassungen für die im Projekt definierte 60MHz Clock des Colorlight-Boards, s.u.):
class NeoPixelEngine(Module, AutoCSR, AutoDoc, ModuleDoc):
"""
NeoPixelEngine class provides the protocol logic to drive NeoPixel LED strips
Usage:
######
#. Fill NeoPixelEngine's local array of GRB values (Green/Red/Blue).
Load ``b24Data2Load`` with a 24-bit (GRB) value.
Indicate the offset (where to store) via writing to ``b8LoadOffset``.
Repeat for all offsets 'til end of array ...
#. Indicate to NeoPixelEngine the actual no. of pixels used by setting up ``b8Len``.
#. Finally, enable processing by setting ``bEnable`` to true (1).
Inputs:
#######
:b24Data2Load: New data to be loaded (24 bits)
:b8LoadOffset: Offset (0..255) into b24GRBArray to load b24Data2Load to
:b4LoadTable: Table index (0..15) where to load to via b8LoadOffset
:b8Len: Length (0..255) of actual 24-bit data entries (i.e. # of NeoPixels)
:bEnable: To enable running (after data preparation)
Output:
#######
:bDataPin: NeoPixel 'Din' pin output (wire to actual output pin ...)
"""
def __init__(self, n_TABLES=1, n_LEDs=3):
# On Colorlight-5A-75B/Lattice ECP5-25 (@i7/4th gen.):
# 16 pins simultaneously driven (w/ 256 NeoPixels each) yield 94%
# Inputs
self.b24Data2Load = CSRStorage(24, reset_less=True,
fields=[CSRField("Data2Load", size=24, description="*Field*: 24-Bit value")],
description="""
Load value (24-Bit G/R/B).
Use ``b8LoadOffset`` first to indicate array location where to store this value.
""")
self.b8LoadOffset = CSRStorage(8, reset_less=True,
fields=[CSRField("LoadOffset", size=8, description="*Field*: 8-Bit value (0..max)")],
description="""
Offset into storage array for 24-bit G/R/B values.
Prepare this one second, then indicate value to store via ``b24Data2Load``.
""")
self.b4LoadTable = CSRStorage(4, reset_less=True,
fields=[CSRField("LoadTable", size=4, description="*Field*: 8-Bit value (0..max)")],
description="""
Table index into storage array for 24-bit G/R/B values.
Prepare this one first, then indicate offset value ``b8LoadOffset``.
""")
self.b8Len = CSRStorage(8, reset_less=True,
fields=[CSRField("Len", size=8, description="*Field*: 8-Bit value (0..max)")],
description="""
No. of active (GRB) entries.
Indicate actual # of elements used (may be less than max!)
""")
self.bEnable = CSRStorage(1, reset_less=True,
fields=[CSRField("Enable", size=1, description="*Field*: bit", values=[
("0", "DISABLED", "``NeoPixel`` protocol not active"),
("1", "ENABLED", "``NeoPixel`` protocol active"),
])
],
description="""
Enable free run (signal start & abort)
""")
# Local data
self.b4Table = Signal(4) # Table rover
self.b8Offset = Signal(8) # Array rover
self.b24GRB = Signal(24) # Current 24-bit data to send
self.b12PulseLen = Signal(12) # Current pulse length
self.b5Count24 = Signal(5) # 24-Bit counter
storage = Memory(24, n_TABLES * n_LEDs)
self.specials += storage
wrport = storage.get_port(write_capable=True)
self.specials += wrport
self.comb += [ # Write to memory
wrport.adr.eq((self.b4LoadTable.storage * n_LEDs) + self.b8LoadOffset.storage),
wrport.dat_w.eq(self.b24Data2Load.storage),
wrport.we.eq(1)
]
rdport = storage.get_port()
self.specials += rdport
self.comb += [ # Read from memory
rdport.adr.eq((self.b4Table * n_LEDs) + self.b8Offset)
]
# Output
self.bDataPin = Array(Signal(1) for bit in range(16)) # To be wired to data pins ...
###
fsm = FSM(reset_state="IDLETABLE") # FSM starts idling ...
self.submodules += fsm
fsm.act("IDLETABLE",
If((self.bEnable.storage==True) and (self.b8Len.storage > 0),
NextValue(self.b4Table, 0), # Start @ 1st table
NextValue(self.b8Offset, 0), # Start @ 1st 24-bit data (mem will be ready next cycle)
NextValue(self.b5Count24, 0), # Bit count 0..23
NextState("IDLE1")
)
)
# G/R/B Word loop entry:
fsm.act("IDLE1", # 1st cycle delay for memory port access
NextState("IDLE2")
)
fsm.act("IDLE2", # 2nd cycle delay ...
NextState("IDLE3")
)
fsm.act("IDLE3",
NextValue(self.b24GRB, rdport.dat_r), # Depends upon b4Table/b8Offset
NextValue(self.b5Count24, 0), # Bit count 0..23
NextState("PREPAREBIT")
)
# 24-bit loop entry:
# Protocol: T0H=400ns/T0L=850ns, T1H=800ns/T1L=450ns, RST>50µs(>50000ns)
fsm.act("PREPAREBIT",
If(self.b24GRB[23],
NextValue(self.b12PulseLen, 47), # Compensate for 1 state changes w/o action ...),
NextState("T1H")
).Else(
NextValue(self.b12PulseLen, 23), # Compensate for 1 state changes w/o action ...
NextState("T0H")
)
)
fsm.act("T1H",
NextValue(self.bDataPin[self.b4Table], 1),
NextValue(self.b12PulseLen, self.b12PulseLen - 1),
If(self.b12PulseLen == 0,
If(self.b5Count24 < 23, # Not final pulse of word
NextValue(self.b12PulseLen, 24) # Compensate for 3 state changes w/o action ...
).Else( # Final word pulse special
NextValue(self.b12PulseLen, 21) # Compensate word load cycles
),
NextState("T1L")
)
)
fsm.act("T1L",
NextValue(self.bDataPin[self.b4Table], 0),
NextValue(self.b12PulseLen, self.b12PulseLen - 1),
If(self.b12PulseLen == 0,
NextValue(self.b5Count24, self.b5Count24 + 1), # Next bit (of GRB)
NextValue(self.b24GRB, self.b24GRB << 1), # Next bit (of GRB)
NextState("NEXTBIT")
)
)
fsm.act("T0H",
NextValue(self.bDataPin[self.b4Table], 1),
NextValue(self.b12PulseLen, self.b12PulseLen - 1),
If(self.b12PulseLen == 0,
If(self.b5Count24 < 23, # Not final pulse of word?
NextValue(self.b12PulseLen, 48) # Compensate for 3 state changes w/o action ...
).Else( # Final word load special
NextValue(self.b12PulseLen, 45) # Compensate for load word cycles
),
NextState("T0L")
)
)
fsm.act("T0L",
NextValue(self.bDataPin[self.b4Table], 0),
NextValue(self.b12PulseLen, self.b12PulseLen - 1),
If(self.b12PulseLen == 0,
NextValue(self.b5Count24, self.b5Count24 + 1), # Next bit (of GRB)
NextValue(self.b24GRB, self.b24GRB << 1), # Next bit (of GRB)
NextState("NEXTBIT")
)
)
fsm.act("NEXTBIT",
If(self.b5Count24 < 24, # Not yet done?
NextState("PREPAREBIT")
).Else( # GRB word finished. More to come?
NextValue(self.b5Count24,0), # Bit count reset for next word
NextValue(self.b8Offset, self.b8Offset + 1), # Prepare offset for later use
NextState("NEXTWORD1")
)
)
fsm.act("NEXTWORD1",
NextState("NEXTWORD2") # Add one cycle for read port propagation!
)
fsm.act("NEXTWORD2",
NextState("NEXTWORD3") # Add one cycle for read port propagation!
)
fsm.act("NEXTWORD3",
If((self.b8Offset < self.b8Len.storage) & (self.bEnable.storage==True), # Still more words to come (& no exit request)?
NextValue(self.b24GRB, rdport.dat_r), # Depends upon b4Table/b8Offset!
NextState("PREPAREBIT")
).Else(
NextValue(self.b12PulseLen, 4095), # >50µs required (3000 not ok!)
NextState("RST")
)
)
fsm.act("RST",
NextValue(self.bDataPin[self.b4Table], 0),
NextValue(self.b12PulseLen, self.b12PulseLen - 1),
If(self.b12PulseLen == 0,
NextValue(self.b4Table, self.b4Table + 1),
NextState("NEXTTABLE")
)
)
fsm.act("NEXTTABLE",
If(self.b4Table < n_TABLES,
NextValue(self.b8Offset, 0), # Start @ 1st 24-bit data
NextState("IDLE1")
).Else(
NextState("IDLETABLE")
)
)
migen erlaubt mit dem eingebauten Simulator den Signaltest (ohne Oszi, in Software). Daraus werden automatisch VCD-Dateien für GTKWave generiert (sollte man installieren!). Hier kann man direkt die programmierte Logik überprüfen …
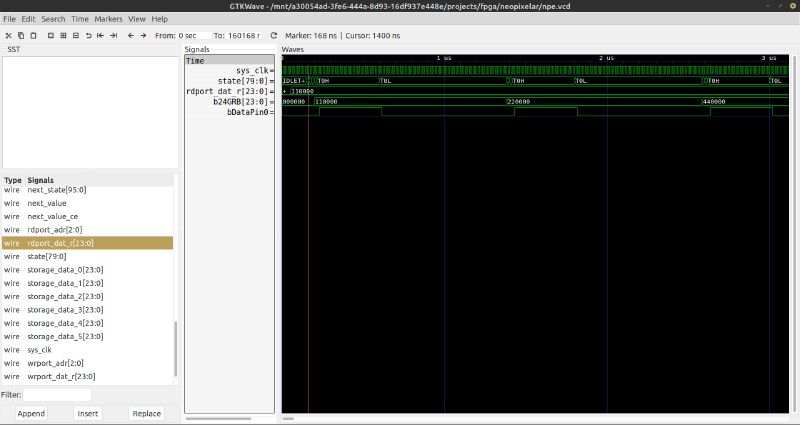
Später (nach dem Flashen, s.u.) nimmt man das Ausgabesignal mit dem Oszi auf, um das ‘Real-world’ Timing zu prüfen und ggf. intern die Zeiten(=>Zähler!) an die Spezifikation anzupassen (der Simulator liefert hier nur Annäherungen …).
Die Erzeugung der automatischen Dokumentation mit Sphinx sieht dann z.B. wie folgt aus (geiles Feature, vergleiche mit den Signaldefinitionen oben in RST-Notation!):

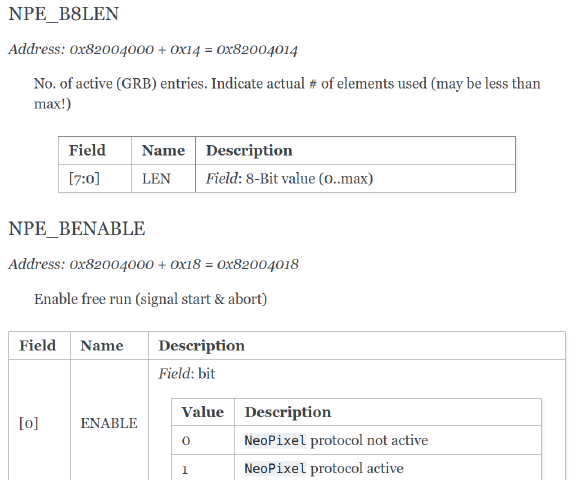
Die Adressangaben beziehen sich auf den Wishbone-System-Bus. Womit wir zum Aufbau des Speichers kommen:

So, oder so ähnlich 😉
3.3 Programmierung
Die Zugriffe auf die Control & Status Register (CSR) werden automatisch passend erzeugt (csr.h), für obige Neopixel-Engine (npe)
z.B. wie folgt (Auszug, vergleiche mit Dokumentations-Sample oben):
// ...
/* npe */
#define CSR_NPE_BASE (CSR_BASE + 0x4000L)
// ...
#define CSR_NPE_BENABLE_ADDR (CSR_BASE + 0x4018L)
#define CSR_NPE_BENABLE_SIZE 1
static inline uint8_t npe_bEnable_read(void) {
return csr_read_simple(CSR_BASE + 0x4018L);
}
static inline void npe_bEnable_write(uint8_t v) {
csr_write_simple(v, CSR_BASE + 0x4018L);
}
#define CSR_NPE_BENABLE_ENABLE_OFFSET 0
#define CSR_NPE_BENABLE_ENABLE_SIZE 1
// ...
Eine Übersicht findet sich auch im Build-Zweig als csr.csv.
Damit läßt sich dann eine Logik zur Ansteuerung wie folgt aufbauen (Auszug aus illumination.c):
// ...
void enable_LEDS(int iEnable)
{
npe_b8Len_write(MAXLEDS); // Prepare length
npe_bEnable_write(iEnable ? 1 : 0); // Enable/disable
}
// ...
Zunächst habe ich die im Basisprojekt fehlende Generierung RAM-Bootbarer Images in einem separaten Shell-Script zusammengebaut (ja, könnte/sollte man als Makefile machen, ich fand’s so übersichtlicher 🙂). Außerdem fehlte die Möglichkeit des Flashens dieses Teils (der ‘Applikation’) im Basisprojekt - wie auch das Löschen.
Die Programm-Teile zur Nutzung der JTAG-Schnittstelle habe ich von Wolfgang übernommen und auf meinen Wunsch hin - falls mal alles schiefgeht - hat Wolfgang noch die Logik zum Löschen des ganzen Flashs beigesteuert.
Im vorliegenden Fall habe ich die Kommandos der eingebauten Shell um einige nützliche Funktionen erweitert (dumpregs, ramboot). Insbesondere ramboot erlaubt das Booten der jeweils anderen (nicht aktiven) RAM-Bank. Da das Projekt eine Netzwerkanbindung (mit Terminal-Umleitung) umfasst, können beliebige Images direkt in den RAM-Bereich geladen werden (mit dem Wishbone-Tool) und dann dort direkt gestartet werden. Da macht das Entwickeln wieder Spaß!
4. NEU: Board-Umbau Ausgänge zu Eingängen
Vor einiger Zeit haben wir mal testweise einen Ausgangstreiber 74HC245 (U28) auf Eingänge (per Richtungsumschaltung, s.u.) umgebaut - ok, nerdyscout hat es umgelötet, ich bin ja eher Grobmotoriker …


Damit können dann sechs 3.3(!) V Eingänge auf J1 und zwei auf J2 genutzt werden. Alternativ geht das gleiche z.Bsp. mit U15 (auf J8 bzw. J7). Wolfgang hat in der Zwischenzeit 74CBT3245 ‘bus switches’ besorgt. Demnächst könnte dann (ohne externe Richtungsumschaltung) jeder I/O-Pin je nach (FPGA-)Konfiguration dynamisch genutzt werden …
5. NEU: DRAM DMA
Auf einem kleineren FPGA - wie im vorliegenden Fall - ist jede Resource kostbar. Der ‘Mißbrauch’ als Speicherablageort
für LED-Daten kann jedoch (weitgehend) umgangen werden, wenn man als Ablageort den Hauptspeicher nutzen könnte …
In migen gibt es bereits FIFOs, in LiteX das LiteDRAM Modul inkl. DMA transfer, da sollte doch was gehen!
Ich habe also eine kleine ‘programmierbare’ Transfereinheit gebaut, die es ermöglicht, für jede LED-Kette einen Ablageort im DRAM zuzuweisen. Die diversen Speicherbereiche (bis zu 63 St.) werden nach Freigabe automatisch abgearbeitet. Interessanter vielleicht: Das eigentliche Applikationsprogramm kann sich nach dem Zuweisen der LED-Daten-Bereiche komplett anderen Aufgaben widmen - das FPGA holt sich seine Daten per DMA direkt aus dem DRAM. Bei Bedarf kann man die LED-Daten im DRAM vom Applikationsprogramm aus direkt überschreiben, sie finden dann den Weg zum FPGA von alleine …
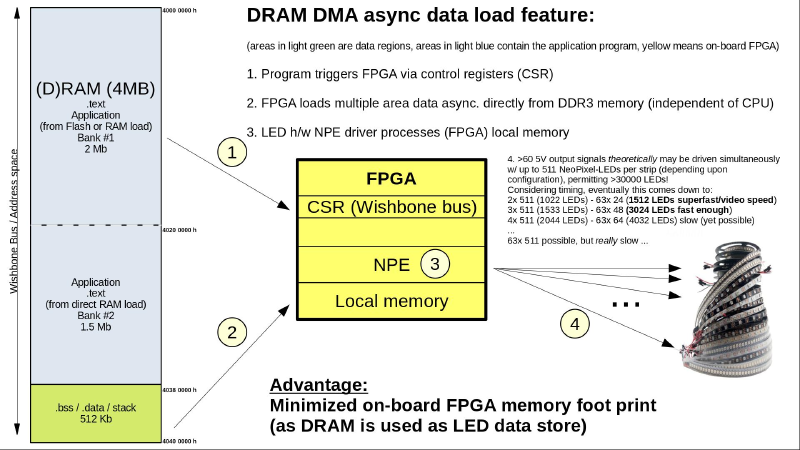
Tatsächlich werden erstaunliche Größenordnungen an LEDs ansprechbar, jedoch trübt der enorme Zeitbedarf bei mehr als ca. 1500 (!) LEDs die Euphorie etwas (dann: nix ‘Echtzeit’!) - vom Stromverbrauch gar nicht zu reden …
Bei der Geschwindigkeit kann noch einmal nachgelegt werden durch Einbindung mehrerer NeoPixel-Engines:
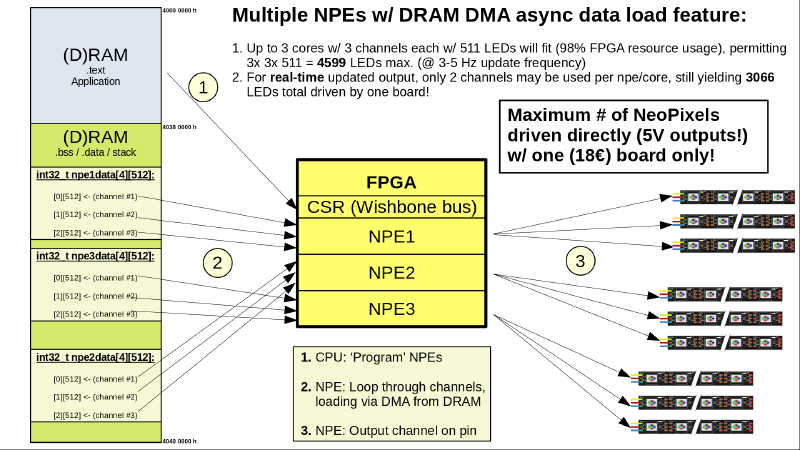
6. Fazit
Zunächst gilt es, eine steile Lernkurve zu überwinden, ab hier - z.B. mit diesem Projekt als Vorlage - geht’s dann aber leicht bergab (um im Bilde zu bleiben 😉).
Tatsächlich bin ich mangels passender Hinweise bzw. unvollständiger Dokumentation (es gilt vor allem ‘Use the source, Luke!’) etliche Irrwege (einige dutzend Stunden) gegangen. Auch schadet es nicht, noch einmal die gcc/as/ld/objdump/readelf Aufrufparameter bzw. Konfigurationsdateistruktur durchzuarbeiten (speziell: RISC-V Toolchain).
Das komplette Projekt steht als Git Repository auf unserem Server zur Verfügung.
7. Ausblick
Was steht noch aus?
- Eine NeoPixel Bibliothek mit vorgefertigten Beleuchtungsfunktionen müsste noch erstellt werden.
- H/W-Umbau einiger Treiber-Bausteine auf bi-directional um wahlweise Eingänge nutzen zu können, z.B. mit I2S (vorgefertigte passende Logik gibt’s bereits …).
Und was ist jetzt mit dem RISC-V Thema? Nun, das wird wohl eine andere Geschichte …