 Mastodon
Mastodon
Um den Einstieg in diesen Artikel zu finden, empfiehlt es sich, die Vorgängerteile zu kennen:
Teil 1: Der NAND-2-Tetris Kurs, ein kleines Defizit & seine Beseitigung
Teil 2: Das eXtended Jack(XJack)/Hack V2(HV2) Ökosystem
Im Folgenden die wichtigsten Neuerungen.
1. Eine weitere Plattform: AARCH64 (ARM v8-A)
Neben den bestehenden Plattformen HV2 und AMD64 gibt es jetzt ein weiteres
Target: AARCH64. Dies ist das (derzeit) gängigste ARM 64-Bit
Format (ARM v8-A). So werden z.B.
- Qualcomm Snapdragon X
- Broadcom BCM271x (mit Raspberry Pi OS 64-bit)
- Apple Mx
grundsätzlich unterstützt. Auch ein AARCH64-(Assembly-)Optimizer ist enthalten.
Damit gibt es jetzt auch drei verschiedene “Defines”. Hier mal ein Beispiel:
public function void printOS() {
var String strOS;
#ifdef AARCH64
let strOS = "ARM v8-A";
#endif
#ifdef AMD64
let strOS = "AMD64/X86_64";
#endif
#ifdef HV2
let strOS = "Hack V2 32-Bit";
#endif
do Output.print("%s\n", strOS);
do strOS.dispose();
}
Binaries können unter Zuhilfenahme von Qemu auch direkt auf dem Entwicklungssystem (Linux amd64/x86_64) ausgeführt werden (Stichwort: binfmt_misc).
2. Automatische HV2E64 Unterstützung (AMD64/AARCH64)
Der Bootcode auf den 64-bit Plattformen sucht im Programmverzeichnis nach
einer Datei .hv2e64. Wenn er diese findet, führt er die dort gelistete
(erste) Programmzeile aus, z.Bsp. wie folgt
../../emulator/hv2e64 --CGD
um den HV2E64 Plattform-Emulator automatisch parallel zur Applikation hochzufahren.
Diese Funktion ist nicht neu, war jedoch eher dürftig kommentiert. Hinzugekommen ist die Fähigkeit, mehrere mit XJack erzeugte Binaries parallel nutzen zu können, d.h. multiple Shared-Memories und programmindividuelle Semaphoren werden unterstützt.
Source & weitere Details: https://git.hacknology.de/kaqu/hv2e64
3. Statische UML-Diagramme
Hinzugekommen ist ein Programm zur Erzeugung von statischen UML-Klassendiagrammen (Format: PNG) aus XJack-Quellen - übrigens unter Zuhilfenahme von ANTLR4 mit Python gebaut …
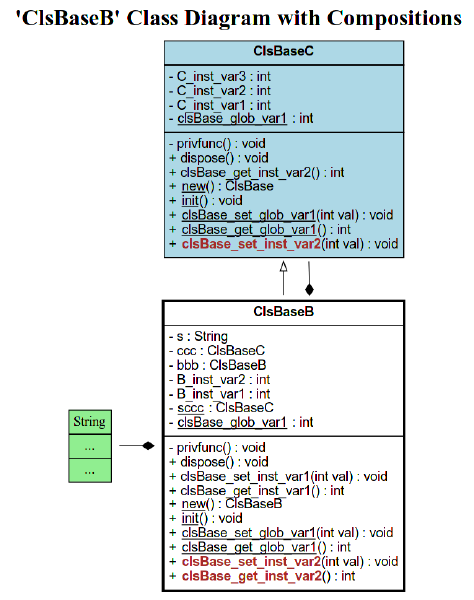
For more on this (& other stuff too)…
4. Exception Handling mit try & catch
Auch schachtelbar! Hier mal ein vollständiges Beispiel:
class Main {
public function int main(int argc, Array argv, Array envp) {
var Array a;
var int v, divisor, eno;
// Preparation, exception or not ...
let divisor = 0; // 0=Div/0 exception, any other ok
let a = Array.new(1); // Array.new(1) ok
// let a = -1; // Will raise exception
// let a = 0; // Same, same ...
do Output.print("Press [Ctrl][C] to initiate default XJack exception handler,!!!\nAny other key to continue ...\n");
let v = Keyboard.waitkey();
// 1. Try memory fault first!
try {
let a[0] = 42; // May raise an exception (if a=0/-1 ... s.a.)!
// 2. Try divide/0 fault next!
try {
do Output.print("Testing int next ...\n");
let v = 1234/divisor; // Should raise an exception!
} catch(eno) {
do Output.print("\n*** Shit, math fault detected!\n");
return 2; // -> shell return (echo $?)
}
} catch(eno) {
do Output.print("\n*** O-ouh, memory access screwed!\n");
return 1; // -> shell return (echo $?)
}
// Yield some results ...
do Output.print("\nv=%d a=%d v/a=%d (eno=%d)\n", v, a[0], v/a[0], eno); // Not reached ...
return 0; // OK
}
}
5. Kontextsensitive Hilfe für XJack Language-Server (VS Code)
Es gibt einen Language-Server für die XJack-Nutzung innerhalb von Visual Studio Code.
Die Hilfstexte dafür werden mittels “--helpgen” Compileroption erzeugt. Der Hilfstext
für Funktion, Methode oder Konstruktor wird mit “/**” eingeleitet und mit “*/” beendet. Dabei wird ein Markdown-Subset unterstützt.
Das kann dann wie folgt aussehen:
/**
Print user hint message, then wait for keyboard entry - terminated by [return] key.
-----------------------------------------------------------------------------------
***message*** **String** User hint message
---
Return: **String** User entered chars. (w/o final CR)
*/
public function String readkeys(String message) {
...
}
6. Variable Argumentzahl
Funktionen, Methoden und Konstruktoren können mit dem Attribut “varargs” gekennzeichnet werden. Damit darf dann eine beliebige Anzahl Argumente übergeben werden. Mittels Sys.vargbase() wird der Argumentzeiger initialisiert, danach kann auf jedes beliebige Argument
mittels Sys.varg(<n>) zugegriffen werden. Auch hierzu ein Beispiel:
varargs public function void vf1(int n) {
var int i;
var int val;
var Array argpt;
let argpt = Sys.vargbase(); // 1st call within function!
do Output.print("vf1:\n");
for(let i=0; i<(n+1); let i=i+1;) {
let val = Sys.varg(argpt, i);
do Output.print("\tArg #%d: %d\n", i, val);
}
}
... calling the function ...
do vf1(0);
do vf1(2, 1, 2);
do vf1(5, 1, 2, 3, 4, 5);
do vf1(7, 1, 2, 3, 4, 5, 6, 7);
...
7. Klassenableitung inkl. Mehrfachvererbung & virtuellen Funktionen
7.1 Klassenableitung und Zugriff mit @super
Es ist jetzt möglich, eine Klasse von einer anderen abzuleiten. Um Methoden in der übergeordneten Klasse (“Superklasse” - eigentlich: Basisklasse & ja, das ist verwirrend ;) von der Abgeleiteten aus aufzurufen, wird als erstes Argument @super verwendet (der this-Objektzeiger). Hierzu ein einfaches Beispiel:
Classes.txt:
AT_DOG=1
AT_CAT=2
ClsDog.jack:
class ClsDog { // This class doesn't even have instance data (but could!)
public method void sound() {
do Output.print("Dog: Woof, woof!\n");
}
}
ClsCat.jack:
class ClsCat {
public method void sound() { // Same, same (s.a.) ...
do Output.print("Cat: Miouw, Miouw!\n");
}
}
ClsAnimal.jack:
class ClsAnimal(ClsDog, ClsCat) {
field int animaltype;
public constructor ClsAnimal new(int type) {
let animaltype = type;
return this;
}
public method void dispose() {
do Memory.deAlloc(this);
}
public method void sound() {
switch(animaltype) {
case AT_DOG: do Dog.sound(@super); // First super class doesn't need explicit specifier!
case AT_CAT: do Cat.sound(@super@Cat); // Methods called as functions with 'this'-pointer adjusted ...
default: do Output.print("Unknown animal?\n");
}
}
}
Main.cls:
class Main {
public function int main(int argc, Array argv, Array env) {
var ClsAnimal cAnimal1, cAnimal2, cAnimal3;
// Create 3 types of animal
let cAnimal1 = ClsAnimal.new(AT_DOG);
let cAnimal2 = ClsAnimal.new(AT_CAT);
let cAnimal3 = ClsAnimal.new(42);
// Let's hear it!
do cAnimal1.sound(); // Should bark
do cAnimal2.sound(); // Should miouw
do cAnimal3.sound(); // Whatever ...
// Kill animals ...
do cAnimal3.dispose();
do cAnimal2.dispose();
do cAnimal1.dispose();
return 0;
}
}
7.2 Mehrfachvererbung
Hierbei werden die öffentlichen Methoden einer (Basis-)Klasse zu den abgeleiteten Klassen exportiert, sie werden “vererbt”. Dadurch können sie aufgerufen werden mit dem Instanz-Objekt der abgeleiteten(!) Klasse (der Compiler macht das notwendige Fix-up).
Methoden werden in der Reihenfolge der Auflistung aber hinter(!) den eigenen Methoden importiert, gleichnamige später auftretende Methoden werden “überschrieben” durch bereits importierte Methoden (d.h. - im Wesentlichen - vom Compiler ignoriert). Auch hierzu ein Beispiel:
ClsBaseA.jack:
class ClsBaseA {
field boolean clsBase_inst_var1;
public constructor ClsBaseA new() {
let clsBase_inst_var1 = 0; // Init vars.
return this;
}
public method void dispose() {
do Memory.deAlloc(this);
}
public method int clsBase_get_inst_var1() {
return clsBase_inst_var1;
}
public method void clsBase_set_inst_var1(int val) {
let clsBase_inst_var1 = val;
}
}
ClsBaseC.jack:
class ClsBaseC {
field boolean clsBase_inst_var1;
public constructor ClsBaseC new() {
let clsBase_inst_var1 = 0; // Init vars.
return this;
}
public method void dispose() {
do Memory.deAlloc(this);
}
public method int clsBase_get_inst_var2() { // Just another name to not being overridden!
return clsBase_inst_var1;
}
public method void clsBase_set_inst_var2(int val) { // s.a.
let clsBase_inst_var1 = val;
}
}
ClsBaseB.jack:
class ClsBaseB(ClsBaseC) {
field boolean clsBase_inst_var1;
public constructor ClsBaseB new() {
let clsBase_inst_var1 = 0; // Init vars.
return this;
}
public method void dispose() {
do Memory.deAlloc(this);
}
public method int clsBase_get_inst_var1() {
return clsBase_inst_var1;
}
public method void clsBase_set_inst_var1(int val) {
let clsBase_inst_var1 = val;
}
}
ClsDerived.jack:
class ClsDerived (ClsBaseA, ClsBaseB) {
field boolean clsDerived_inst_var1;
public constructor ClsDerived new() {
let clsDerived_inst_var1 = 0; // Init vars.
return this;
}
public method void dispose() {
do Memory.deAlloc(this);
}
public method int clsDerived_get_inst_var1() {
return clsDerived_inst_var1;
}
public method void clsDerived_set_inst_var1(int val) {
let clsDerived_inst_var1 = val;
}
}
Main.jack:
class Main {
public function int main(int argc, Array argv, Array env) {
var ClsDerived cDerived; // This instance carries everything within ...
let cDerived = ClsDerived.new();
do cDerived.clsBase_set_inst_var1(123); // clsBaseA (listed 1st(!) in cDerived)
do cDerived.clsDerived_set_inst_var1(456); // Just local in cDerived
do cDerived.clsBase_set_inst_var2(1337); // Actually: clsBaseC (listed in B->C)
do Output.print("\n%d=123? %d=456? %d=1337?\n", cDerived.clsBase_get_inst_var1(),
cDerived.clsDerived_get_inst_var1(),
cDerived.clsBase_get_inst_var2());
do cDerived.dispose();
}
}
7.3 Virtuelle Funktionen
Virtuelle Methoden erlauben das Umleiten von Aufrufen innerhalb einer Klasse zu abgeleiteten Klassen (“lateral calls”). Das heißt, man kann als virtuell gekennzeichnete Methoden einer Basisklasse in abgeleiteten Klassen überschreiben - auch wenn die Basisklassen nur noch kompiliert vorliegen!
Zusammen mit dem @super-Operator (s.o.) erlaubt das die elegante Implementation von Wrappern und den typischen Entwurfsmustern. Ein Beispiel:
TheBase.jack: // This class assumed existing even compiled already ...
class TheBase { // An external class, maybe not known/understood by the programmer ...
// Simple original result print
virtual method void print_result(int iResult) {
do Output.print("result=%d", iResult);
}
method void do_some_intricate_processing(Array arData) {
// ... a loop over all data elements assumed ...
do print_result(arResult[i]); // Would usually call its local function ...
}
}
JackTheWrapper.jack: // The 'enhanced' custom class
class JackTheWrapper(TheBase) { // The programmer's wrapper for the 'unknown' remote class
// This method overrides the base class method by the same name
virtual method void print_result(int iResult) {
do Output.print("Before->");
do TheBase.print_result(@super, iResult); // NOTE: Method called As class function ...
do Output.print("<-After\n");
}
// Processing called from elsewhere, say 'main program'
method do_eval(Array arData) {
do do_some_intricate_processing(arData);
}
}
Wenn aus dem Hauptprogramm <JackTheWrapper instance>.do_eval(<parameter>) aufgerufen wird, könnte das folgende Ausgaben produzieren:
Before->result=15439<-After
Before->result=328<-After
... etc. ...
Technisch stecken dahinter statische & dynamische Sprungtabellen an Klassen bzw. Instanzen und ein wenig vom Compiler erzeugter Glue-Code (VM/IL) während der Initialisierung wie auch zur Laufzeit (ok, es brauchte drei Anläufe bis das lief … ).
Buildtool Notwendigkeit
Zirkuläre Referenzen sind nicht erlaubt - auch nicht über mehrere Ableitungsebenen hinweg. Außerdem müssen abgeleitete Klassen NACH den Basisklassen übersetzt werden.
Um eine Durchsetzung
dieser Regeln zu erzwingen, gibt es ein neues Build-Tool (“XJBuildTool”). Dies erzeugt im Programmverzeichnis die Datei Classes.txt, deren Angaben zur Reihenfolge vom Compiler - sofern vorhanden - ausgewertet werden.
8. Design Patterns
Wäre es jetzt möglich, typische Entwurfsmuster (Design Patterns - “DPs”) in XJack zu realisieren? Zunächst muß mal ins Thema eingestiegen werden, hier zum Beispiel:
“Design Patterns in UML” zeigt 14 typische DPs in drei Kategorien (“Creational”, “Structural” & “Behavioural”).
Es zeigt sich, daß einer Realisierung nichts im Wege steht! Hier mal ein Beispiel für das Factory-Pattern.
Die vier “Fabriken” - mit dem eigenen UML-Generator (s.o.) erzeugt:
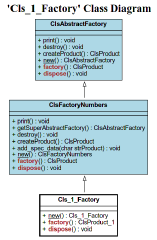
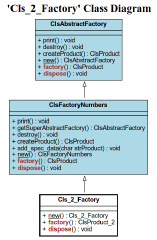
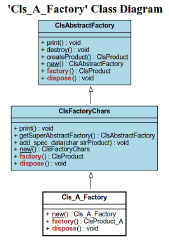
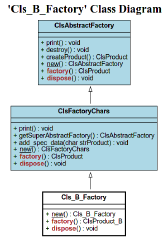
Und hier die Ausgabe:
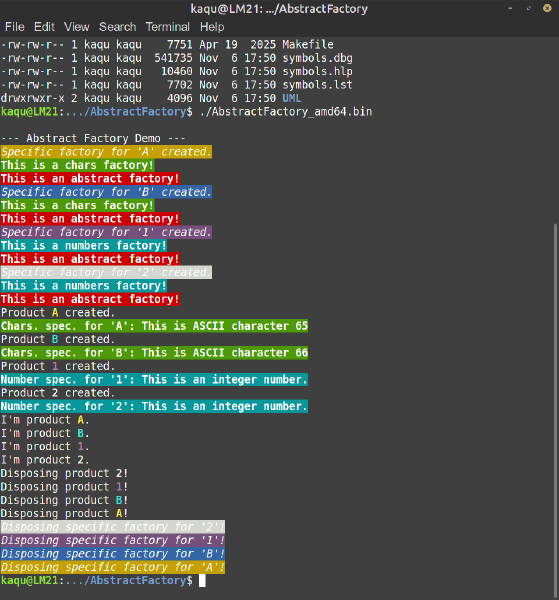
Weitere Implementierungen finden sich auf unserem Git-Server hier.
9. foreach/in für neue Mengen-Klassen wie List, Stack, Queue, Fifo, Range & Dictionary
Bewaffnet mit den neuen Möglichkeiten virtueller Funktionen könnte man doch jetzt so etwas wie einen Iterator für Mengen aller Art bauen?
Man nehme ein Basiselement (SetElement) und eine
allgemeine Verwaltungsstruktur (Set) und sehe eine Konvention vor, mit der Programmierer das
Schema auf eigene Varianten abbilden können. Das kann dann z.B. wie hier ausgeführt aussehen.
Wenn man jetzt dem Compiler noch beibringt, diese neuen Strukturen zur Erzeugung von VM-Code zu
verwenden, könnte man folglich auch ein Konstrukt wie foreach & in zusammenstricken, mit dem
wiederum man dann quasi beliebige Mengentypen wie Liste, Dictionary etc. verarbeiten könnte …
Für die abgeleiteten Klassen List, Stack, Queue, Fifo, Range und Dictionary können
jetzt die ebenfalls bereits vorbereiteten Klassen ValueElement bzw. KeyValueElement (aufbauend
auf SetElement) verwendet werden. Oder auch eigene abgeleitete Klassen …
foreach/in wird in zwei Varianten eingesetzt:
foreach <element> in <set> { ... }
foreach <var>=<element>.<elementfunction> in <set> { ... }
Hier ein Dictionary-Beispiel zur Verdeutlichung:
public function void TestDictionary() {
var SetElement e;
var Dictionary myDictionary;
var String sValue;
do Output.print("\n------------ Dictionary test -------------\n");
let myDictionary = Dictionary.FromValues(3,
KeyValueElement.new("#1#", "1:lkjkasdf"),
KeyValueElement.new("#2#", "2:kfivke"),
KeyValueElement.new("#3#", "3:ieocvef")
);
// Simplest approach
do Output.print("Length=%d\n", myDictionary.length());
foreach e in myDictionary {
do Output.print("%s -> %s\n", e.do_getKey(), e.do_getValue());
}
// Single element access
do Output.print("Some key retrieval ...\n");
let e = myDictionary.getKeyValue("#3#");
if (e > null) {
do Output.print("#3# -> %s\n", e.do_getValue());
}
let e = myDictionary.getKeyValue("#99#");
if (e = null) {
do Output.print("#99# not found (which is ok)!\n");
}
do Output.print("Removing element(#2#).\n");
do myDictionary.remove("#2#");
foreach e in myDictionary {
do Output.print("%s -> %s\n", e.do_getKey(), e.do_getValue());
}
// Direct value access
do Output.print("Direct value access ...\n");
foreach sValue=e.do_getValue() in myDictionary {
do Output.print("%s\n", sValue);
}
do myDictionary.dispose();
}
Womit sich folgende Ausgaben produzieren lassen:
------------ Dictionary test -------------
Length=3
#1# -> 1:lkjkasdf
#2# -> 2:kfivke
#3# -> 3:ieocvef
Some key retrieval ...
#3# -> 3:ieocvef
#99# not found (which is ok)!
Removing element(#2#).
#1# -> 1:lkjkasdf
#3# -> 3:ieocvef
Direct value access ...
1:lkjkasdf
3:ieocvef
10. Die Funktion map() des Mengentyps Set
Die Mengenklasse Set unterstützt eine Mappingfunktionalität. Hierbei kann eine Anwenderfunktion
die Elemente der Menge einzeln verarbeiten wie folgt:
public function SetElement squaremapper(SetElement input) {
var int v;
let v = input.do_getValue(); // Value of RangeElement
// NOTE: Instance values need to be copied/duplicated
// because of possible multiple disposal otherwise!
return ValueElement.new(v * v); // Squared!
}
Im aufrufenden Programm - hier mal mit der Range-Klasse - sieht das dann wie folgt aus:
public function void TestRange() {
var Range r;
var Set sout;
var ValueElement iv;
var int iVal;
// Create set with values [5 .. 10]
let r = Range.new(5,10,1);
// Map range values with example function (s.a.): f(x) = x²
let sout = Set.map(r.getData(), Sys.app_start_rom_base() + squaremapper);
foreach iVal=iv.getValue() in sout {
do Output.print("x²=%d\n", iVal);
}
do sout.dispose();
do r.dispose();
}
Was folgende Ausgabe produzieren sollte:
x²=25
x²=36
x²=49
x²=64
x²=81
11. Async & await für vereinfachtes Multi-Threading
Aufbauend auf den existierenden Klassen Task, Interrupt & Semaphore wurde zunächst ein Modul
Async mit einem vereinfachten Interface (“Facade-Pattern” s.o.) erstellt.
Darauf aufsetzend gibt es
jetzt für den vereinfachten Zugriff “Syntactic Sugar” in Form der neuen Keywords async und
await für den Compiler. Hierbei sind einige Konventionen zu beachten:
async <asHandle> = <user_function_pointer> [, <userdata_pointer>];
Hierdurch wird ein paralleler Thread gestartet der die angegebene Funktion aufruft, optional mit Nutzerdaten.
Das Ergebnis einer längeren Verarbeitung wird dann später mittels
await <resultcode> = <asHandle>;
abgeholt. Falls die Anwenderfunktion noch nicht beendet ist, wird der aufrufende Thread blockiert bis die Anwenderfunktion endet. Deren Ergebnis wird dann an die aufrufende Funktion übergeben und diese fortgesetzt.
Die Anwenderfunktion könnte also wie folgt aussehen:
public function int userfct(Async asHandle, int stop, Array arUserdata) {
...
If (stop) { // Is this the last call before termination? → clean-up & return result
return 42;
}
...
if (my_termination_condition) { // Your criteria!
do asHandle.finish(); // Terminate this thread regularly
return 0; // Wait for final call w/ stop flag set ...
}
...
do Tasks.yield(); // Maybe permit others to do their share as well?!
return 0; // Whatever ...
}
public function int main(int argc, Array argv, Array env) {
var Array arUserData;
let arUserData = Array.new(1);
let arUserData[0] = 1337; // Start value
async async_handle = my_async_routine, arUserData; // Spawn thread ...
... do whatever has to be done on the calling thread ...
// If the user function will run infinitely:
// do async_handle.cancel(); // Request cancellation from the outside ...
// If the user function will terminate all by itself you may retrieve its status:
if (~async_handle.done()) {
do Output.print("\nUser function thread not yet done?! Let's go to sleep ...\n");
} else {
if (async_handle.cancelled()) {
do Output.print("\nUser function aborted!\n");
else {
do Output.print("\nUser function terminated regularly.\n");
}
}
// Ok, lets pick up final return value of user function
await i = async_handle; // Will block until spawned thread terminates
do Output.print("\nStop flag processed yields: %d\n", i);
do arUserData.dispose(); // Clear task data
return 0;
}
12. Coroutinen, Generatoren & Streams mit co & gen
12.1 Coroutinen
Coroutinen sind zustandsbehaftete Funktionen, d.h. sie verlassen ihren Kontext nicht.
Wie geht das, also wie kommt man denn dann zum Aufrufer zurück?
Unter Zuhilfenahme von Transferfunktionen wie yield und kill!
Kommt einem irgendwie bekannt vor? Exakt. Die Verwendung ist analog zur Nutzung beim Multitasking, d.h. der aktuelle Kontext wird (ggf.) stillgelegt und die CPU für einen anderen wartenden Kontext freigegeben. Der Unterschied: Diese Umschaltung erfolgt nie preemptiv sondern nach Vorgabe durch den Programmierer. Wo aber liegt da der Vorteil?
Da alle Coroutinen im gleichen Thread liegen, ist der Kontextwechsel mit minimalen Overhead verbunden (“super-lightweight” threading) - im Wesentlichen müssen nur PC, SP und ein oder zwei andere Register der CPU umgeschaltet werden.
Prinzipbedingt erfolgt der Kontextwechsel in genau definierten Kodezeilen - und nicht “irgendwo” - daher muss auch nichts zusätzlich beachtet und ggf. gesichert werden. Also: Geringe CPU-Last, kleiner Speicheroverhead! Und schnell …
Die Coroutinen-Erzeugung und Initialisierung sind als Sprachfeature integriert wie folgt:
co <coHandle> = <user_function_pt> [, <userdata_pointer> [, <upstreamco>, <downstreamco>] ];
Coroutinen (in XJack) müssen einigen Konventionen folgen:
① Sie geben nie einen Wert zurück, sind also vom Typ void.
② Drei Argumente werden übergeben:
- die aktuelle Coroutinen-Instanz
- ein reservierter Parameter (derzeit nicht genutzt, Null)
- ein Anwenderwert, typischerweise ein Zeiger auf Anwenderdaten
③ Der reguläre Ausstieg erfolgt nicht durch das Verlassen mittels return sondern über die Funktion <coroutine-Instanz>.kill(), daher ist für die Funktionskennzeichnung kein (weiteres) gesondertes Attribut notwendig.
④ Blockierende (Kontextwechsel erzwingende) Funktionen wie <coroutine-Instanz>.receive() können
im normalen Ablauf beliebig eingestreut werden.
⑤ Oder eben freiwillige CPU-Abgaben mittels <coroutine-Instanz>.yield().
Eine Beispielcoroutine könnte also wie folgt aussehen:
public function void my_user_function(Coroutine coR, int _reserved, Array arUserData) {
var int iValue;
// Whatever the init code may be ...
do Output.print("my_user_function() entry!\n");
while(true) { // Loop forever (almost!)
let iValue = coR.receive(); // Will block w/o data (which is 'normal'!)
do Output.print("Received: %d\n", iValue);
if (iValue < 0) { // Just some kill criteria
break; // for now: unconditionally
}
}
// Some cleanup if nec.
do Output.print("my_user_function() exit!\n");
do coR.kill(); // Final call, will not return!
}
Was passiert hier? Nach Initialisierung (die “Nachricht”) wird eine Dauerschleife betreten.
Darin wird versucht einen Integerwert (von “Upstream”) zu empfangen. Sofern noch kein Wert zur
Verfügung steht (bei Erstaufruf: immer!), blockiert die Coroutine hier und die Kontrolle wird
an den Aufrufer (von co!) zurückgegeben.
Bei erfolgender Datenübermittlung (send) wird die Blockierung aufgehoben und der empfangene
Wert ausgegeben. Sofern das Abbruchkriterium erfüllt ist (Wert < 0), wird die Dauerschleife
verlassen und die Coroutine ordentlich mittels <coroutine-Instanz>.kill() beendet.
Von außen könnte das so aussehen:
var Coroutine coR1; // Our co-routine instance ...
co coR1 = my_user_function; // Create (& call) the co-routine code & data
// Actual job – send some data along ...
do coR1.send(1234);
do coR1.send(1337);
do coR1.send(-1); // Termination signal (s.a.)
do coR1.dispose(); // Cleanup
Hier wird mittels des neuen Schlüsselworts co ein Coroutinen-Kontext erzeugt und die Funktion
my_user_function erstmalig aufgerufen. Wenn diese blockiert (zur Erinnerung: in receive()!),
erfolgt die Fortsetzung in der erzeugenden Funktion.
Im Beispiel werden dann einige Werte an die Coroutine mittels <coroutine-Instanz>.send()
übermittelt. Bei Übermittlung der Abbruchbedingung (zur Erinnerung: < 0!) beendet sich die
Coroutine selbst, Kontrolle wird wieder an den Erzeuger zurückgegeben und der Coroutinen-Kontext
kann dort wieder freigegeben werden.
Die Ausgabe sollte also wie folgt aussehen:
my_user_function() entry!
Received: 1234
Received: 1337
Received: -1
my_user_function() exit!
12.2 Generatoren
Auch eine “Generator/Iterator”-Variante von Coroutinen als Sprachfeature ist verfügbar:
gen <coH> = <user_fct_pointer> [, <userdata_pointer> [, <upstreamco>, <downstreamco>] ];
Diese Variante sendet/erzeugt Daten anstatt sie zu empfangen. Hier ein Beispiel für einen (zugegeben: umständlichen!) Schleifenzählergenerator:
public function void loop(Coroutine coR, int _reserved, Array arUserData) {
var int i;
for(let i=arUserData[0]; i<arUserData[2]; let i=i+arUserData[1];) {
do coR.send(i); // Will block ...
}
do coR.kill(); // Final call, will not return!
}
Hier werden die übergebenen Nutzerdaten auch wirklich verwendet. arUserData enthält
den Schleifenstart- & Abbruchwert sowie das Inkrement (ja, nur aufwärts zählend …).
Wenn diese Coroutine aktiviert wird, sendet sie den nächsten Wert “downstream”. Sofern sie kann! Ansonsten blockiert sie (z.Bsp. mangels freiem Empfangsslot). Nach Ablauf der Schleife beendet sie sich selbst.
Im Aufrufer läuft der folgende Code:
var Coroutine coR1;
var Array my_user_data;
var int rc;
let my_user_data = Array.new(3); // Allocation
let my_user_data[0] = 5; // start value
let my_user_data[1] = 1; // max value
let my_user_data[2] = 10; // increment
gen coR1 = loop, my_user_data;
// Actual generator data receiver
while (true) {
let rc = coR1.next(); // Try to receive a value
if (coR1.is_not_stopped()) { // Empty indication by stop flag
do Output.print("Loop: %d\n", rc);
} else {
break;
}
}
do coR1.dispose(); // Cleanup
Das gen Schlüsselwort erzeugt einen neuen Generatorkontext der nicht sofort
gestartet wird (was aber unter Verwendung von <coroutine-Instanz>.yield() möglich wäre).
Analog zur Verwendung in anderen Programmiersprachen wird <coroutine-Instanz>.next()
verwendet um die Generatordaten abzuholen.
Um die Gültigkeit der empfangenen Daten sicherzustellen, muß auf so etwas wie “EOF” geprüft
werden. Dazu wird die <coroutine-Instanz>.is_not_stopped() Funktionalität genutzt.
Abschließend wird der Generatorkontext wieder freigegeben.
Damit sollte folgende Ausgabe produziert werden:
Loop: 5
Loop: 6
Loop: 7
Loop: 8
Loop: 9
12.3 Streams
Eine interessante Anwendung für Coroutinen ist das “Streams”-Konzept, bei dem eine Quelle Daten erzeugt die durch eine Kette von Verarbeitungsschritten geschickt werden (“downstream”).
Mit Coroutinen können diese Schritte elegant entkoppelt werden. Auch unterschiedlich große Datenblöcke können bearbeitet, aggregiert oder zerlegt werden.
Beispielcode findet sich hierzu in Kapitel 3.23, Abschnitt (c) …
13. Einfache Konstanten
Wenn im Projektverzeichnis die Datei Constants.txt vorhanden ist, werden die darin enthaltenen
Konstanten in den Quellen vor Übersetzung ersetzt - so eine Art Präprozessor für Arme …
Eine Beispieldatei Constants.txt:
// This is a comment line ...
MY_INT = 1234
MY_STRING = "ABC"
Und die Nutzung:
... (usable in any source file within project directory)
var String s;
...
let s = MY_STRING;
do Output.print("Your constants are: %d and %s\n", MY_INT, s);
do s.dispose();
...
Dies Feature wird auch vom XJack-Language-Server für VS Code unterstützt.
14. Exportverhalten beeinflussen mit public und private
Wie vielleicht schon oben aufgefallen: Es gibt jetzt die Attribute public und private
für Funktionen, Methoden und Konstruktoren.
public ist der Default und darf auch weggelassen werden. Es bewirkt eigentlich keine
Veränderung gegenüber früher, die Funktion wird exportiert und kann daher von anderen
Klassen/Modulen verwendet werden.
private verhindert den Export (durch “Name-Mangling”). Insbesondere bei Verwendung des XJack-Language-Servers ist man dann dankbar für den aufgeräumten Namespace (bei Vorschlägen) …
15. Main.main Anpassung
Die Funktion Main.main wurde geändert und muß jetzt den üblichen Konventionen folgen, d.h.
argcenthält die Anzahl der übergebenen Argumente inargvargvist ein Array von Strings mit den übergebenen Argumenten (Kommandozeile u.ä.)envpist ein Array von Strings mit den Wertpaaren des Environments (Arrayende: Null)
Außerdem ist zwingend ein Rückgabewert vorzusehen.
Class Main {
...
public function int main(int argc, Array argv, Array envp) {
...
return 0; // Return value required!
}
}
Auf der HV2-Platform lädt die Standard-Shell die Datei .config, die die entsprechenden
Wertpaare für das Environment enthält.
Wertpaare können abgefragt und geändert/gesetzt werden mit den entsprechenden Funktionen der Environment-Klasse. Siehe HV2OS-API, Kapitel 3.4.