 Mastodon
MastodonFür ein besseres Verständnis wird dringend geraten, zuerst diesen Artikel hier durchzuarbeiten …
Motivation
Dies ist jetzt die angedrohte RISC-V Geschichte! Nachdem ich vor 3 Monaten die Neopixel-FPGA Lösung beendet hatte, war klar, das auch die Realisierung einer kompletten CPU (‘Turing-Maschine’) möglich sein würde.
Wenn sich jetzt Google & Apple ihre eigenen CPUs bauen (lassen), warum dann nicht auch jeder andere? [*]
Das wär’ doch mal was - eine selbst gebaute CPU in migen/LiteX/Python auf einem FPGA!
[*] Eine rhetorische Frage, mittlerweile baut ‘gefühlt’ jede größere Bude oder Uni ihre eigenen Chips (siehe https://github.com/riscv/riscv-cores-list u.ä.)!
1. RISC-V Einstieg
Warum gerade eine RISC-V CPU?
-
Das war im Herbst letzten Jahres nun mal die Ausgangsfrage …
-
Warum nicht? RISC-V ist in den letzten Jahren ein regelrechter Hype - und ich mach’ doch jeden Blödsinn mit … Realitätsnäher: Es gibt jede Menge Referenz-Implementierungen (nicht zuletzt auch in LiteX - leider jedoch nur in Verilog & nmigen, nicht in migen - oder ich hab’ sie nicht gefunden …).
Ich fand diese Sourcen eher spärlich dokumentiert (Wolfgang ist hier anderer Meinung - ☮ man!) und auch nicht vollständig (keine F-Extension für IEEE754 Fließkommabehandlung etc.) - mal schaun, ob sich zumindest im FPU-Bereich die Lage verbessern läßt … -
Auf dem von mir bereits früher verwendeten Colorlight-Board (s.Artikel) ist bereits eine RISC-V (Soft-)CPU aktiv (‘vexriscv’), damit hatte ich bereits (Assembler-) Übung aus dem letzten Projekt - immer eine schön stumpfe Begründung!
Um reinzukommen habe ich mir zunächst ein paar YouTube Videos zum Thema RISC-V angesehen. Dabei fand ich auch diesen Vortrag von Megan Wachs (von SiFive - ‘der’ RISC-V Firma!) in dem - unter anderem - drei Buchvorschläge gemacht werden. Nachdem ich mich separat über die jeweiligen Inhalte informiert hatte, entschied ich mich für das ‘Mittlere’ (Patterson, Waterman ‘The RISC-V Reader’) - das ist schön knapp.

Es beschreibt die RISC-V Architektur (‘ISA’ - Instruction set architecture), die zugrunde liegenden Ideen der Beteiligten (von den ‘Erfindern’ selbst - also total distanzlos …), enthält Assembly-Beispiele & Grafiken (z.B. die ‘Reference Card’, s.u.) sowie eine Liste aller Befehle inkl. der optionalen Befehlserweiterungen - die bei RISC-V eine große Bedeutung haben! Außerdem enthält es einige Rüpeleien gegen andere Architekturen (ARM/Intel/MIPS), sehr lustig 🎃! Als einzig satisfaktionsfähige (Alternativ-)Architektur gilt hier übrigens Xtensa (also ESP) mit seinem Register-Fenster …
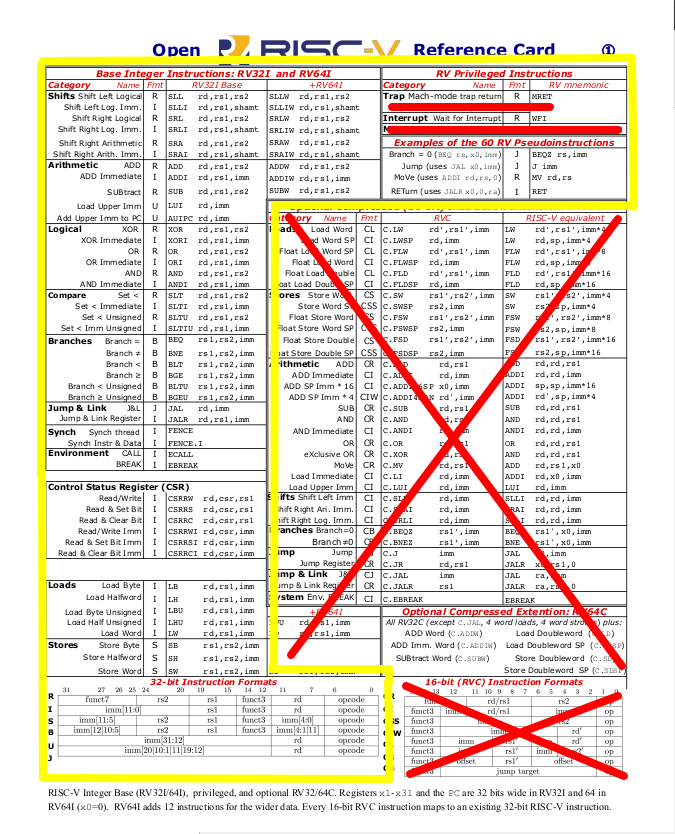
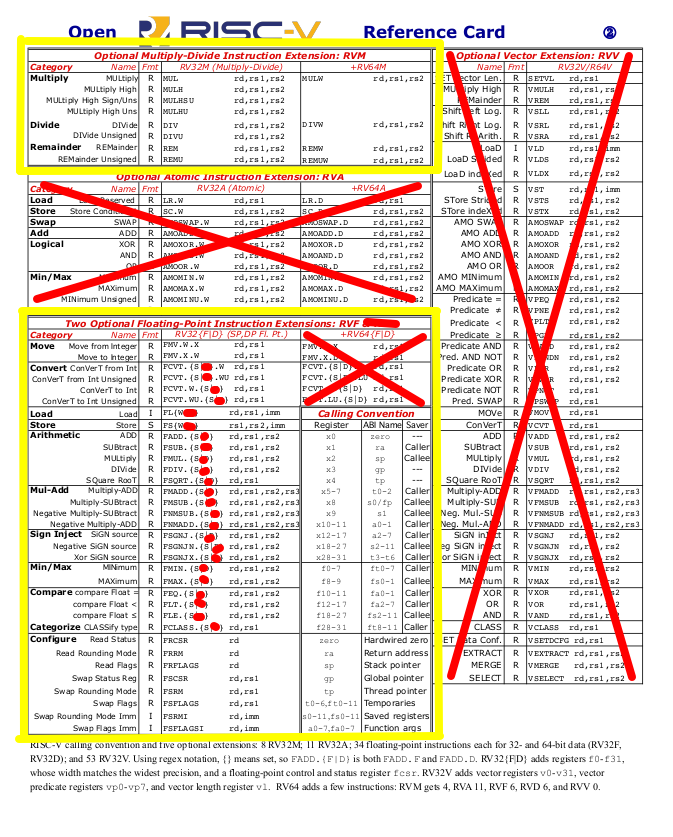
Obige Grafiken zeigen die in diesem Projekt realisierten RISC-V Ausbaustufen (gelb gerahmt):
- I (Base): Integer (Basis)
- M (Extension): Integer multiply (& divide) support
- F (Extension): Floating point (32-bit) support
Die Bezeichnung für die im Projekt realisierte CPU lautet daher offiziell: RV32IMF.
Es steht daher nur der ‘Machine Mode’ zur Verfügung (d.h. nur eine Auswahl der Control & Status Register [CSR]).
Die (ISA-)Spezifikation kann natürlich auch direkt hier bezogen werden:
Vol.1
& Vol.2.
2. Was macht eine CPU (‘Central Processing Unit’)?
Eine CPU liest Werte aus dem Speicher (‘das Programm’ oder auch ‘die Applikation’). Diese Werte werden als Befehle (‘Opcode’) vom Prozessor interpretiert. Im Ergebnis werden bei der Interpretation Daten aus dem Speicher gelesen (ja, parallel zum Laden des Programms!), in den internen Prozessor-Registern je nach Opcode verschoben bzw. verarbeitet und dann Ergebnisse ggf. zurück in den Speicher geschrieben (jedenfalls typischerweise …).
Bei RISC-V ist das in den Befehlen sauber getrennt:
- Es gibt Befehle zum Laden von Werten aus dem Speicher (und NUR dafür)
- Es gibt Befehle zum internen Bearbeiten (und NUR dafür)
- Es gibt Befehle zum Schreiben von Werten zurück in den Speicher (und NUR dafür)
- Außerdem gibt es noch Verzweigungs- bzw. Sprungbefehle
Mal ’ne Referenz: Eine CPU ist folglich Teil einer konkreten Form einer Turing-Maschine (umständlichlicher ging gerade nicht 💀!). Das Symbolband ist der Speicher, der Schreib-/Lesekopf bilden Load- & Store-Unit der CPU. Zustandsregister und Instruktionstabelle werden als interne Register und interne Verarbeitungslogik umgesetzt.
3. Wie baut (‘synthetisiert’) man eine CPU?
Hierzu wusste ich zunächst recht wenig, daher entschloß ich mich, ein paar Vorträge zum
Thema zu hören (YouTube!). Ich entschied mich für MIT 6.004
aus dem Herbst 2019 - bis L15 hab’ ich’s mir dann auch reingetan …
Leider wird dort mit bluespec/minispec gearbeitet - KEIN migen! Ein bisschen Transferleistung
mußte also noch zusätzlich erbracht werden 🏋.
Hätte ich mich an alle dort gegebenen Tipps gehalten, wäre das Resultat wahrscheinlich überzeugender
ausgefallen … hier habe ich einfach Hardware so aufgebaut, wie ich einen Software-Emulator
geschrieben hätte.
Das hieß auch, erst einmal einen Automaten bauen der einen (kleinen) Speicherbereich aus dem DRAM
lädt, und jedes (32-Bit-)Wort einzeln anpacken kann. Außerdem mußte der Automat fernsteuerbar
sein (über den Wishbone-Systembus) zwecks Debugging - was auch hieß: Parallel muß gleich ein
Debugger hochgezogen werden (um überhaupt testen zu können, was so intern abgeht … 🤔 ).
Von hier aus kann man sich dann von Befehl(-simplementation) zu Befehl(-simplementation) hangeln.
4. Praktische Umsetzung
Zunächst beließ ich die mitgelieferte ‘vexriscv’ CPU parallel noch in Betrieb. Hiermit passte immerhin noch die ‘Basis’ Integer-Version von RISC-V auf’s FPGA (bei ca. 1/2h Stunde Übersetzungslauf), genannt RV32I (für 32-Bit) mit 32 X-Registern (Integer).
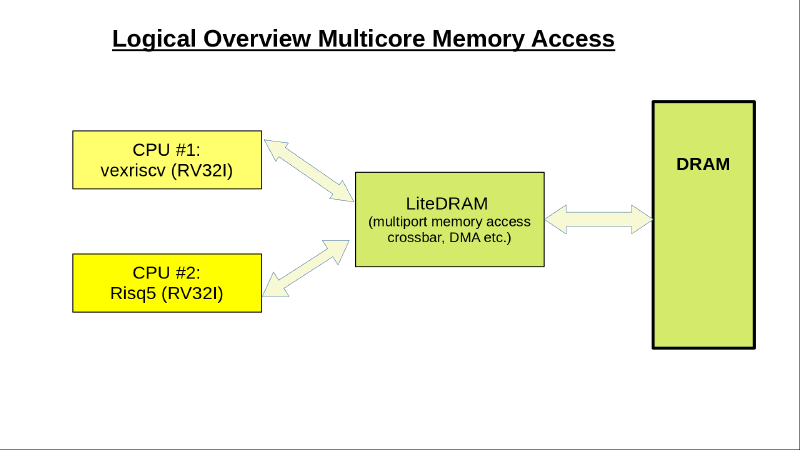
Um die M-Extension zu realisieren, musste ich jedoch bereits die 2. CPU entfernen (Konfigurationsänderung).
Anschließend habe ich gleich noch den integrierten Cache, den Wishbone-Zugriff und Flash/BIOS-Zugriff
entfernt. Damit sanken die Übersetzungszeiten in migen/LiteX dann auf ca. 10 Minuten (alle Zeiten gemessen
in VM mit 4 Kernen auf i7/3rd gen.).
Jetzt konnte ich auch den 32-Bit Fließkommateil (‘F-Extension’) noch komplett integrieren - mit einer
Einschränkung: Es passen nur noch jeweils vier X- & F-Register in das Lattice ECP5-25 FPGA (von eigentlich 32
Stück)! Die Logik geht aber komplett drauf - bei durchaus erträglichen Übersetzungszeiten von um die
20 Minuten.
Die Logik arbeitet mit 2 oder 5 Addressbits für das interne Registerfile, kann folglich 4 bzw. 32 Register
adressieren (lediglich zwei Variablen müssen angepasst werden um ‘full blown’ auf einem größeren FPGA zu
arbeiten …).
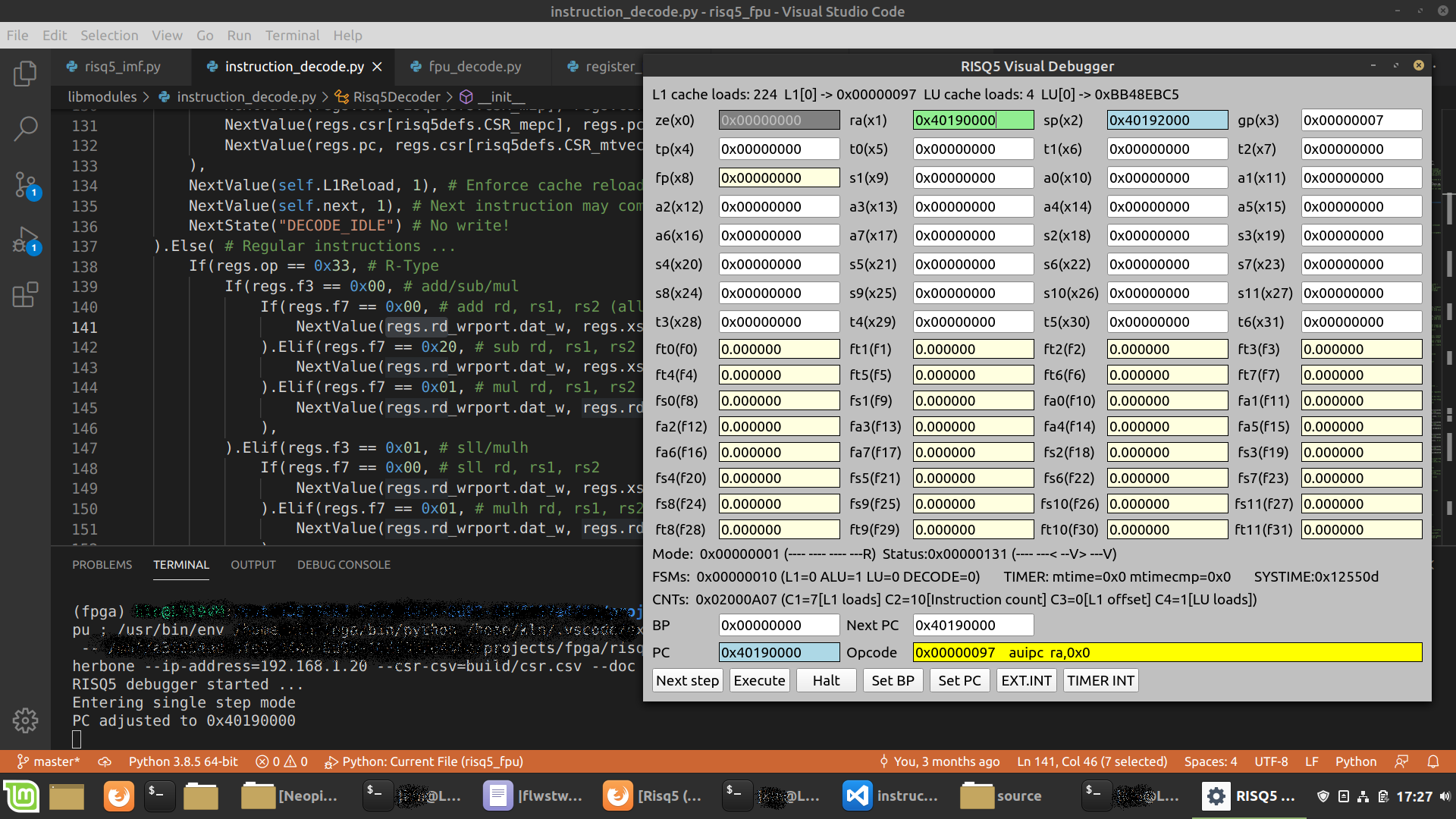
5. Debugging
Zunächst habe ich im normalen BIOS-Terminal gearbeitet (wie gehabt), die laufende Applikation (auf der ‘alten’ vexriscv CPU!) IST dann der Debugger. Später bin ich darauf gekommen, das Debugging-Interface am Wishbone-Systembus direkt über Ethernet anzusprechen, ein entsprechender PC-seitiger ‘Server’ ist im Wishbone-Tool bereits enthalten. Damit kann der Debugger komplett separat in Python erstellt werden und auf dem PC laufen (s. Übersichtsbild oben).
Hier mal die grundsätzliche (boardseitige) Anbindung:
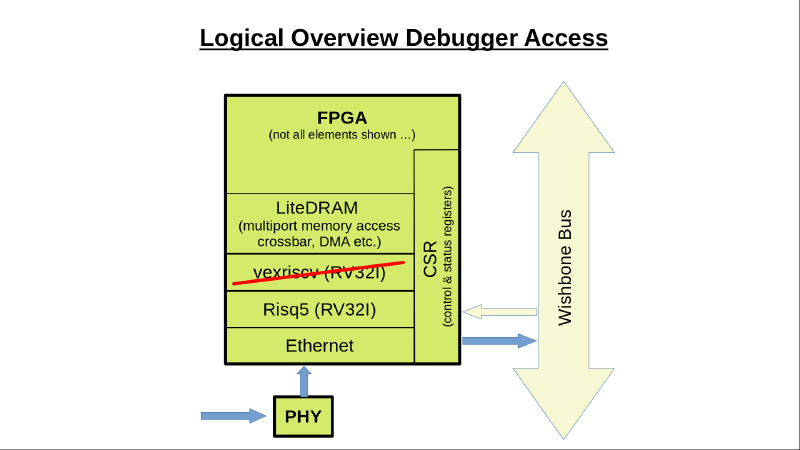
Bild zeigt den Aufbau noch mit dem zweiten ‘alten’ Core parallel.
6. Instruktionsverarbeitung
Der Verarbeitungskern (‘core’) besteht aus Programmladeeinheit (L1-Cache - korrekter wäre wohl L0?),
der Datenladeeinheit (LU - load unit) und der komplementären Speichereinheit (SU - store unit),
dem Basisdecoder und dem FPU-Decoder sowie der (über den Wishbone-Systembus fernsteuerbaren)
Abarbeitungslogik (hier etwas irreführend als ALU bezeichnet 🤔, eigentlich handelt es sich eher um
sowas wie ‘data flow’).
Der L1-Cache lädt sich zunächst selbst von der Boot-Adresse (RISC-V: 0h!) und signalisiert dann ‘Bereit’
an die ALU (deren Programmzähler ‘PC’ ebenfalls zunächst auf 0h steht 🎉 !), diese lädt daraufhin den ersten
Befehl (‘opcode’) und prüft, ob der Laufstatus freigegeben ist (der Debugger erlaubt sowohl Single-Stepping
wie auch ‘Freilauf’ - übrigens auch bis ‘Breakpoint’ …).
Außerdem kann der PC im Debugger geändert werden, die ALU signalisiert dann dem L1-Cache ein Neuladen ab
PC und wartet entsprechend. Auch bei sonstigen Bedarfen (Interrupt-Routine, Sprüngen im Programmcode in einen
Bereich außerhalb des gerade geladenen Cache-Ranges - oder auch schlicht nächster Befehl …) signalisiert
die ALU dem L1-Cache Entsprechendes.
Bei freigegebener Ausführung (‘Execution’) wird der Opcode mit dem Decoder verarbeitet.
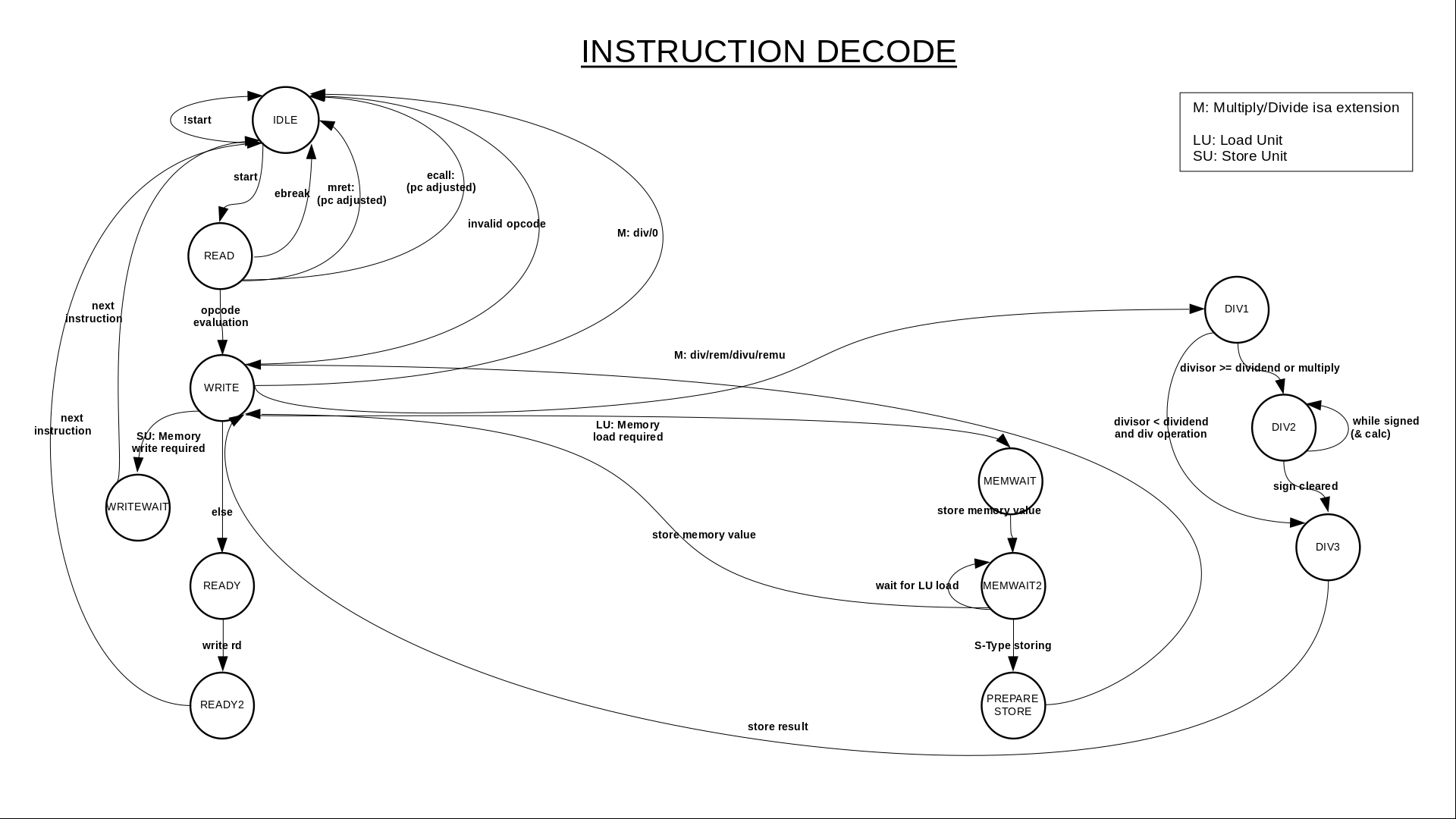
Die Grafik zeigt den Basisdecoder(-Automaten) inkl. dem Teil für die M-Extension (integer multiply/divide).
Die F-Extension ist erst später entstanden als obige Grafik und als Automat nicht sehr ergiebig insofern, als viele Befehle einfach eigene Verarbeitungsketten durchlaufen da hier nur wenige Konverterfunktionen gemeinsam genutzt werden können. Generell triggert der Basisdecoder den FPU-Decoder und wartet anschließend schlicht auf Fertigmeldung …
7. Test
Für das Testen kann der gcc für RISC-V genutzt werden. Über Aufrufparameter kann die Zielplattform exakt eingestellt werden. Praktisch hieß das zunächst (im Projektablauf) für RV32I übersetzen, später für RV32IM und letztlich für RV32IMF. Die Unterschiede zeigen sich deutlich im generierten Assemblat.
Ein Beispiel:
unsigned int result;
int m1,m2;
m1 = 12345;
m2 = 67890;
result = m1 * m2;
m2 = result / m1;
gcc Parameter -march=rv32i -mabi=ilp32 (für RV32I ohne Optimierungen):
...
addi sp,sp,-32 # Local variable reservation on stack (notice: extra space allocated!)
sw ra,28(sp) # Notice: Additional save because of lib. call!
lui a5,0x03
addi a5,a5,57 # 12345
sw a5,12(sp) # m1=
lui a5,0x11
addi a5,a5,-1742 # 67890
sw a5,8(sp) # m2=
lw a1,8(sp)
lw a0,12(sp)
auipc ra,0x0
jalr ra # 0x68 Library call (unlinked) a0 = __mulsi3(a0,a1)
mv a5,a0
sw a5,4(sp) # result=
lw a5,12(sp)
mv a1,a5
lw a0,4(sp)
auipc ra,0x0
jalr ra # 0x84 Library call (unlinked) a0 = __udivsi3(a0,a1)
mv a5,a0
sw a5,8(sp) # m2=
...
-march=rv32im -mabi=ilp32 (für RV32IM):
...
addi sp,sp,-16 # Local variable reservation on stack
# Notice: Additional space for ra save (ra='return adress')
# but not used as there is no function call
lui a5,0x3
addi a5,a5,57 # 12345
sw a5,12(sp) # m1=
lui a5,0x11
addi a5,a5,-1742 # 67890
sw a5,8(sp) # m2=
lw a4,12(sp)
lw a5,8(sp)
mul a5,a4,a5 # a5 = a4 * a5
sw a5,4(sp) # result=
lw a5,12(sp)
lw a4,4(sp)
divu a5,a4,a5 # a5 = a4 / a5
sw a5,8(sp) # result=
...
.
Und noch ein Beispiel mit Floats:
float result;
float m1,m2;
m1 = 1.234;
m2 = 6.789;
result = m1 * m2;
m2 = result / m1;
-march=rv32i -mabi=ilp32 (für RV32I):
...
addi sp,sp,-32 # Local var. reservation
sw ra,28(sp) # Due to lib. calls ...
lui a5,0x0
lw a5,0(a5) # From address: 0x0
sw a5,12(sp) # Constant load fixup during link phase?!
lui a5,0x0
lw a5,0(a5) # From address: 0x0
sw a5,8(sp)
lw a1,8(sp)
lw a0,12(sp)
auipc ra,0x0
jalr ra # 0x68 library call: a0 = __mulsf3(a0,a1)
mv a5,a0
sw a5,4(sp)
lw a1,12(sp)
lw a0,4(sp)
auipc ra,0x0
jalr ra # 0x80 library call: a0 = __divsf3(a0,a1)
mv a5,a0
sw a5,8(sp) # m2=
...
-march=rv32imf -mabi=ilp32 (für RV32IMF):
...
addi sp,sp,-16
lui a5,0x40192
flw fa5,64(a5) # from address: 0x40192040
fsw fa5,12(sp) # m1=
lui a5,0x40192
flw fa5,68(a5) # from address: 0x40192044
fsw fa5,8(sp) # m2=
flw fa4,12(sp)
flw fa5,8(sp)
fmul.s fa5,fa4,fa5 # f15 = f14 * f15 (actual register file 'raw' names)
fsw fa5,4(sp) # result=
flw fa4,4(sp)
flw fa5,12(sp)
fdiv.s fa5,fa4,fa5 # f15 = f14 / f15
fsw fa5,8(sp) # m2=
...
.
Bei RV32I werden für viele Dinge Library-Routinen benötigt, die auf RV32IMF ’native’ (und damit: erheblich schneller) laufen können. Außerdem kann offensichtlich Stack-Space gespart werden (und der Code schrumpft auch!). Interessant: Fließkommakonstanten werden separat abgelegt …
Das Laden geschieht wieder über das Wishbone-Tool, zum Testen in einen festen Bereich (wäre aber grundsätzlich egal - Hauptsache DRAM!). Die Ladeadresse ist so gewählt (0x40190000), daß sie nicht mit den Bereichen des ‘alten’ Kerns (vexriscv) kollidiert.
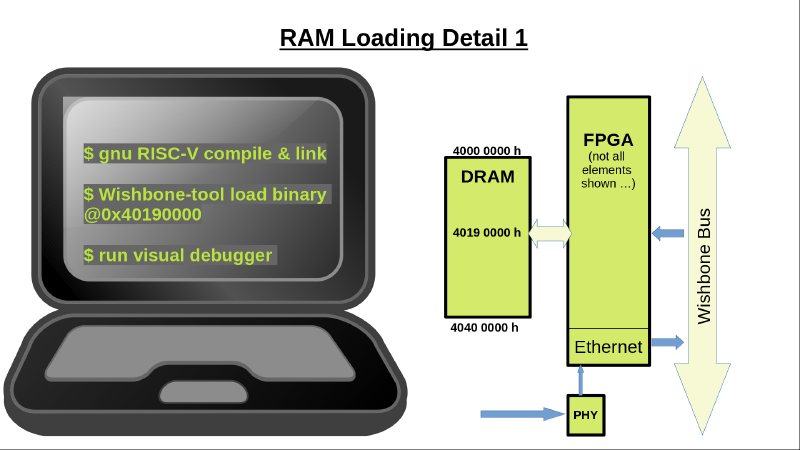
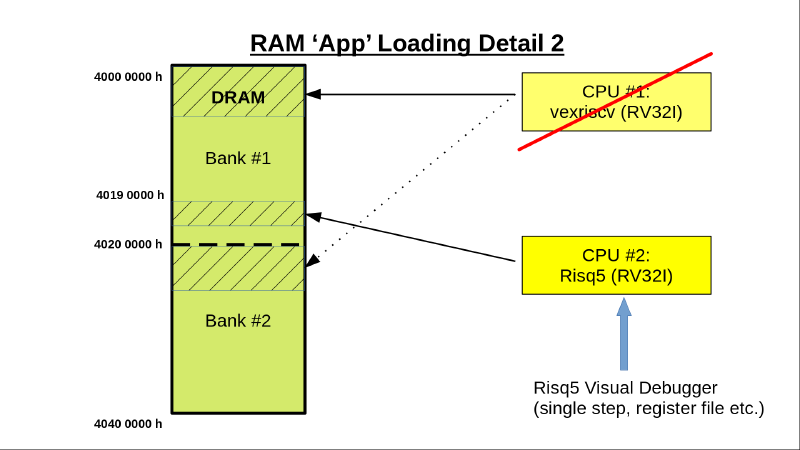
.
8. F-Extension: Einfach-genaue 32-Bit-Fließkommazahlen gemäß IEEE 754
Fliesskommazahlen sind kein ’natürliches’ Format für Computer (das wäre ein Binärsystem). Es bedarf spezieller Annahmen und einer speziellen Behandlung um sinnvolle Ausgaben produzieren zu können. Die Umsetzung von dezimal zu binär basiert auf der Festlegung eines festen Formats (gemäß IEEE 754 - einem Standard, den heutzutage jeder Prozessorhersteller anbietet), hier für 32-Bit Zahlen wie folgt:
0000 0000 0000 0000 0000 0000 0000 0000
Seee eeee eMMM MMMM MMMM MMMM MMMM MMMM
S ist das Vorzeichen ('sign', 0='+' / 1='-')
e ist der Exponent (8 bit)
M ist die Mantisse (23 bit)
Dezimalzahlen werden gemäß folgender Formel dargestellt:
xd = (-1)^S * 1.M * 2^(e - 127)
Es wird also eine fixe eins vor dem Komma angenommen, der Bereich der Mantisse liegt dann zwischen eins und zwei. Außerdem wird der Exponent von 0..255 auf den Bereich 128..-127 transformiert. Man kann das mit diesem Simulator selbst testen.
Wenn man glaubt, alles verstanden zu haben (also nach reichlich 🌍-Recherche … die bei mir immer ein bisschen U.S.-lastig ausfällt, wahrscheinlich weil ich DDG benutze 🤔?), kann es nützlich sein, das Gelernte zunächst einmal in einem Testprogramm auszuprobieren (die FPGA-Übersetzung wäre einfach zu zeitaufwendig!).
Hier mal ein Beispiel für ein Testprogramm für das flt.s mnemonic (Vergleichen auf f1 kleiner f2 - ’less-than’), das Ergebnis landet später als 0 oder 1 in einem (integer) x-Register:
// Extraction
#define IEEE754_SIGN(v) ((unsigned int)(v) & 0x80000000)
#define IEEE754_EXP(v) (((unsigned int)(v) & 0x7F800000) >> 23)
#define IEEE754_MANT(v) ((unsigned int)(v) & 0x007FFFFF)
// Synthesis
#define SIGN_IEEE754 0x80000000
#define EXP_IEEE754(v) ((v) << 23)
#define MANT_IEEE754(v) (v)
unsigned int f_lt_s(float f1, float f2)
{
unsigned int *ui1 = (unsigned int *) &f1, *ui2 = (unsigned int *) &f2;
// 0. Dissection
signed char e1 = IEEE754_EXP(*ui1) - 127;
signed char e2 = IEEE754_EXP(*ui2) - 127;
unsigned int m1 = IEEE754_MANT(*ui1);
unsigned int m2 = IEEE754_MANT(*ui2);
// Simple sign compare ahead
if(IEEE754_SIGN(*ui1) ^ IEEE754_SIGN(*ui2)) { // Sign mismatch? That's easy!
if(IEEE754_SIGN(*ui1)) // f1 negative -> hence f1 smaller!
return 1;
else // f2 negative, f1 is not less than
return 0;
}
// Same sign: Compare exponents, then (maybe) mantissas
if(e1 < e2) { // f1 smaller (absolute number)?
if(IEEE754_SIGN(*ui1)) // But in negative range?
return 0; // f1 not as small as f2!
else // Positive
return 1;
}
else { // f2 smaller/equal absolute value
if(e2 < e1) { // f2 smaller (absolute value)
if(IEEE754_SIGN(*ui1)) // But f1 in negative range?
return 1;
else // Positive
return 0;
}
else { // Equal exponents?
if(m1 < m2) { // Compare mantissas: f1 smaller
if(IEEE754_SIGN(*ui1)) // But negative?
return 0;
else // Positive
return 1;
}
else { // f2 smaller/equal
if(IEEE754_SIGN(*ui1)) // But negative?
return 1;
else // Positive
return 0;
}
}
}
}
Das sieht doch nur noch halb so kompliziert aus! Von hier ist es dann ein Kinderspiel zur migen Umsetzung (‘Python’!).
9. Das Projekt
Das Projekt-Repository findet sich hier auf unserem Git-Server. Es enthält reichlich Kommentierung und vielleicht noch nützliche weitere Informationen zur Umsetzung (wenn auch vermutlich zu wenig - wie immer …).
10. Mängel
- Das Ganze muß noch auf eine andere Zielplattform mit größerem FPGA verschoben werden (für jeweils volle 32 Integer & Float-Register)
- Der Zugriff auf den Wishbone-Systembus durch die CPU selbst ist derzeit nicht vorhanden (weil ich das Ding komplett von Scratch hochgezogen habe - und damit nicht analog zu den mit LiteX installierten Alternativ-Kernen - 🗣 Depp!).
- Dann kann auch das BIOS wieder aktiviert werden um überhaupt von Flash booten zu können …
- Die Performance ist wahrscheinlich recht gruselig (kein Pipelining, keine µOps) … aber echte Messungen stehen noch aus.
- Grausamer Flächenverbrauch (für einen echten Chip), schlechte Energiebilanz
- fence/fence.i sind ohne Funktion (wie: nop)
11. Ausblick & Ideen
- Wenn man die Sache mit den Fließkommazahlen einmal verstanden hat, sollte es nicht schwer sein, ähnlich aufgebaute Formate zu realisieren. Wie wäre es als Nächstes mit FP16 (gemäß IEEE 754-2008) innerhalb eines KI-Beschleunigers? Mal schaun …
- Mit diesem Rahmen könnte man sich eigentlich auch eine eigene 32-Bit ISA überlegen - vielleicht
mit einer Spezialisierung für bestimmte Aufgaben (DSP, ik hör’ dir trapsen)?
Falls universelle ISA: Und dann den gcc anpassen - der Compilerbau soll ja einige Fortschritte gemacht haben seit den Zeiten meines alten ‘Dragon Books’ …
Interessante Möglichkeiten tun sich auf!